How many pages does Microsoft's search engine Bing.com hold in its index? Following the idea of Maurice de Kunder we can roughly estimate the size of Bing's index being 300 million pages.
Following Maurice de Kunder's approach we perform queries for a set of query terms,
Next we can compare the two frequencies and estimate the size of the unkown collection. When the assumption holds that the distributional properties of the two collections are rather similar, our estimates should also be quite accurate. For example, if the term 'der' (german masculine definite article corresponding to 'the' in the english language) occurs in 80% of the pages in the representative collection and Bing showes 210 million results, then we can estimatiotimate Bing's index size to be about 210 x 80% = 262.5 million pages. To get a more reliable estimate we not only use high frequency terms but also terms with lower frequency and average the results.
There are some short comings when comparing to Maurice' method:
"der" site:de.wikipedia.org, which gives 1,260,000 results. Again
Maurice used a representative sample of the web, where wikipedia might
well have different distributional properties.An example of my queries using Bing and de.wikipedia.org as the
reference collection (Using Google search with special command
site:de.wikipedia.org):

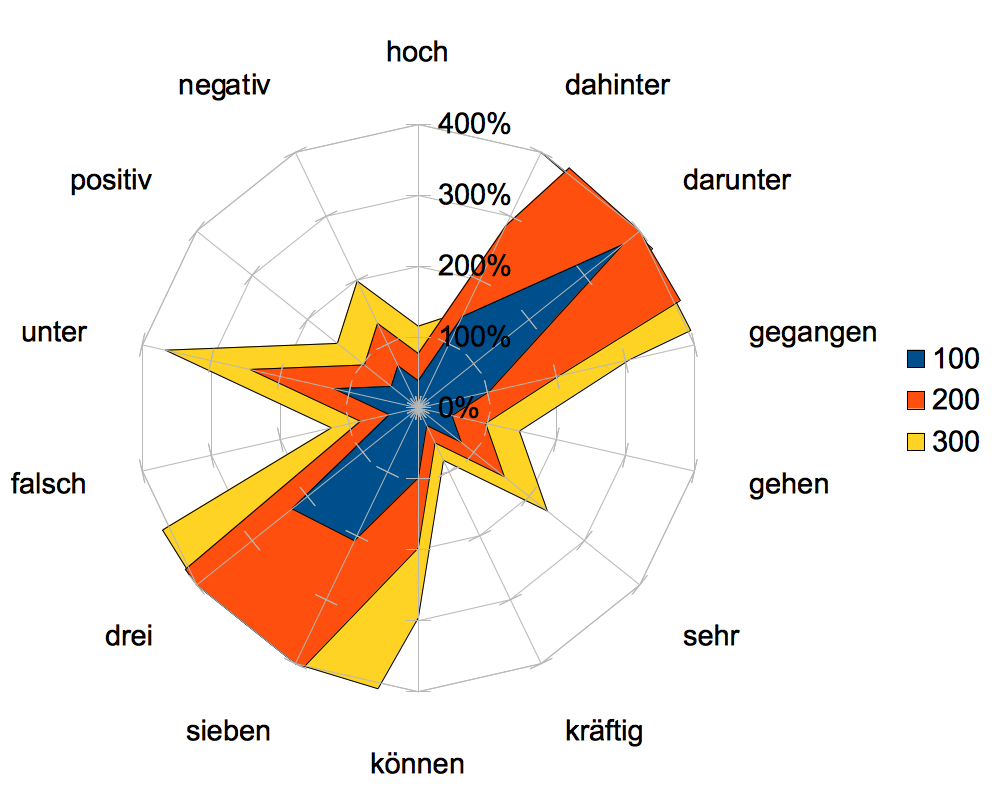
Here are the query terms and frequencies results
| Term | Bing (in thousands) | de.wikipedia.org | 100 | 200 | 300 |
|---|---|---|---|---|---|
| hoch | 33300 | 128,0 | 38% | 77% | 115% |
| negativ | 2960 | 19,6 | 66% | 132% | 199% |
| positiv | 5280 | 25,7 | 49% | 97% | 146% |
| unter | 51300 | 626,0 | 122% | 244% | 366% |
| falsch | 5910 | 24,8 | 42% | 84% | 126% |
| drei | 21000 | 479 | 228% | 456% | 684% |
| sieben | 5440 | 113 | 208% | 415% | 623% |
| können | 51100 | 504,0 | 99% | 197% | 296% |
| kräftig | 2270 | 6,2 | 27% | 55% | 82% |
| sehr | 29600 | 230,0 | 78% | 155% | 233% |
| gehen | 16600 | 81 | 49% | 98% | 146% |
| gegangen | 1510 | 15,4 | 102% | 204% | 306% |
| darunter | 3110 | 115 | 370% | 740% | 1109% |
| dahinter | 1170 | 16,7 | 143% | 285% | 428% |
And finally a net chart to visualize the results from the above table. As you can see 300 million seems to be a good estimate for the german index of Bing, provided that my assumptions hold (most terms are well above 100% with the only exception of "kräftig"):